People wanting to get involved in the football analytics online community often ask “where can I find data?”. It’s a valid question to ask and the answer is either 1) pay a lot of money for it 2) learn to collect it from online sources.
Repeated requests for data touched a nerve with Neil Charles lately, posting:
https://twitter.com/neilcharles_uk/status/778180206280441860
I therefore thought I would writes a mini-series of quick bite-sized tutorials for using R and the web-scraping package rvest to collect some data from the popular website transfermarkt.com. Although the data we will collect is not that insightful, my hope is that by showing the process it will help people learn how easy it is to get started in their hunt for data. It will also show a little about how I am learning R myself which goes a little like: Have a Goal >> Code >> Hit a Wall >> Google Solution >> Code >> Hit a Wall … * repeat * >> Reach Your Goal (or thereabouts).
This is a very basic series of tutorials and is unashamedly aimed at the total beginner and will include the following elements:
Part 1 : Introduction & Scrapping a List of Web Links of Clubs
Part 2 : Loop Through the Web Links and Scrape a List of Web Links of Players
Part 3 : Loop Through the Player Links and Collect the Name and Height of the Players [up soon]
Part 4 : Using ggplot2 to Create a Density Graph of Players Values within the EPL [up soon]
DISCLAIMER: The data we collect from transfermarkt.com should only be used for private use
Stage 1 : The Setup
You will need to download R as well as the popular IDE RStudio. Installing the programmes is pretty straight forwards but start with R then afterwards install RStudio. Quicklinks: R then RStudio.
The final tool you will need is a SelectorGadget extension for your browser, I use the Chrome Extension which works smoothly and easy to install. SelectorGadget will help us find the minimal css selector for the element on the webpage that we want to scrape. This can be done through the browsers built-in ‘inspect’ tools but its a much harder and longer process than with SelectorGadget.
Stage 2 : RStudio Setup
Once you have everything installed open up RStudio and you should be confronted with a layout similar to the below:
Firstly, click on the ‘new file’ icon and then select R Script:

You will then have the following layout:
If you want a further tour around RStudio check out this video.
RStudio comes with many ‘packages’, which significantly expand on the base utilities of the programme but we can also add further packages, rvest being one of them. Installing packages is thankfully extremely easy by running the following in the console (bottom right section):
install.packages("rvest")
We will install some more packages later on but for now once the package in installed we are good to go.
Stage 2 : Scraping a List of URLs
In Part 1 we will start very simply by taking the English Premier League Overview Page on transfermarkt.com and extracting the links to all EPL Club Overview Pages. Its a baby step but we must start somewhere.
In the top left-panel is the new R Script you opened, we are going to write our code in this window and then run it sporadically to check our progress.
Step 1 : Reading a Webpage into RStudio
Type the following lines into to the RScript window (try not to cut and paste, as you aren’t really learning and by typing it will start to sink in):
library(rvest) URL <- "http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1" WS <- read_html(URL)
library(rvest)
This line loads the library rvest to we can utilise it, even though we have installed the package already we still need to load it for use. We could do this within the console but having it in the script will ensure that the rvest package that we utilise in the code is loaded the next time we use this script. If a package is not loaded we will get error messages that are sometimes hard to work out.
URL <- “http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1”
This line saves the web address we want to scrape data from to the variable of ‘URL’ for further us (I always use URL but essentially this can be called anything).
WS <- read_html(URL)
This line takes the webpage we allocated to the the URL variable and ‘reads’ the webpage into RStudio saving the information into a variable we choose to name WS (short for Web Scrape – but essentially this can be called anything).
Select all of the code and press the ‘run’ button.
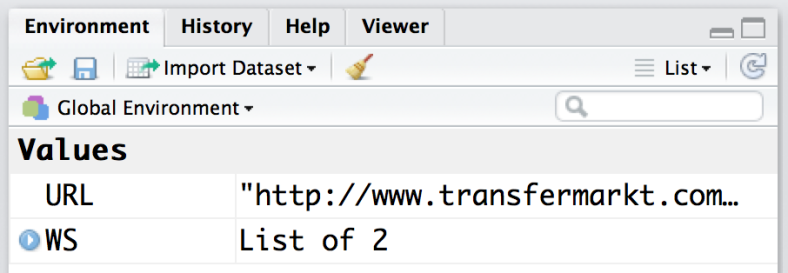
In the top right panel under the ‘Environment’ tab we can see that we have a URL saved and the webpage successfully ‘read’ and saved within ‘WS’. We will not be displaying the webpage within R but rather extracting information for that saved element.
Step 2 : Scrapping A List of Web Links
First open up http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1 in the browser you have installed SelectorGadget plugin/extension for – for me that’s Chrome.
It’s a good idea to watch the following video to get an idea of how SelectorGadget works, although set by set instructions are below. Open your plugin by pressing the icon and you will then be presented with a box overlaying the browser and when you hover over elements you will see an orange border appear.

The idea of SelectorGadget is that you select the element you want to scrape. Go ahead and click on one of the clubs and you will notice that that the club names are highlighted in yellow but also the club logos.
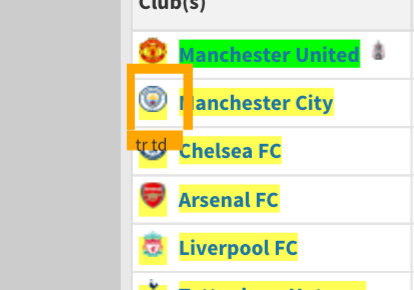
You now have to narrow down your selection by clicking on yellow elements that you want to remove from the selection. Each time you remove an element the plugin will narrow down the options significantly. Until you are left with the element you want to scrape, for us its just the club names.
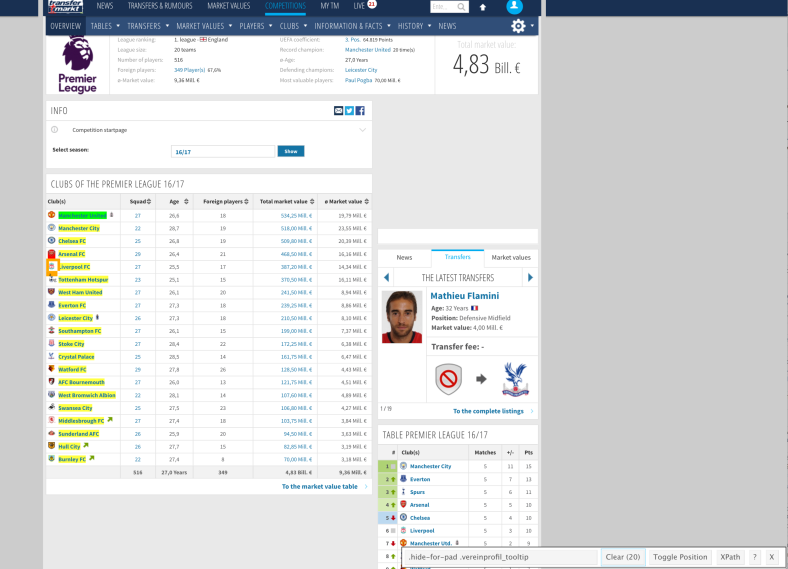
You should have the following in the plugins overlaid box:

We have now narrowed things down to the 20 club names which have the unique CSS identifier of “.hide-for-pad .vereinprofil_tooltip”. Fantastic, we are making progress and back to Rstudio.
We add one line to our script:
library(rvest)
URL <- "http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1"
WS <- read_html(URL)
URLs <- WS %>% html_nodes(".hide-for-pad .vereinprofil_tooltip") %>% html_attr("href") %>% as.character()
I will break our new line down for us:
URLs <-
This segment means that everything to the right will be saved as URLs
WS
Is simply selecting our read webpage
html_nodes(“.hide-for-pad .vereinprofil_tooltip”)
Selects all elements that match the unique CSS identifier that we ascertained from our work with SelectorGadget.
html_attr(“href”)
This selects an attribute of the matched elements and we have selected the “href” attribute which is the link address.
as.character()
Saves the selected items as a string
%>%
This is called piping and is used to link bits of code together and pass information from one bit of code to the next. It makes coding is R much quicker and more logical.
Select our new line and press run and once the code as run, in the console type : print(URLs)
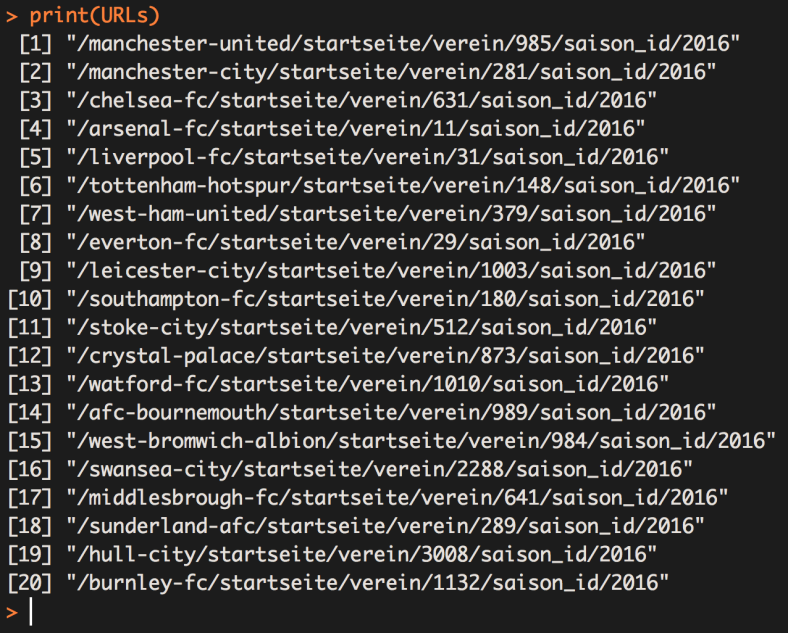
Great progress, we have now successfully scraped the links to all club overview pages within the EPL for the 2016/17 Season.
Step 3 : Completing the Links
The sharp eyed among you will notice the selected links are missing “http://transfermarkt.com” and will therefore not work when we come to use them in Part 2. We rectify this using the ‘paste0’ function which we can use to stick strings together.
library(rvest)
URL <- "http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1"
WS <- read_html(URL)
URLs <- WS %>% html_nodes(".hide-for-pad .vereinprofil_tooltip") %>% html_attr("href") %>% as.character()
URLs <- paste0("http://www.transfermarkt.com",URLs)
I will break our new line down for us:
URLs <-
Once again this segment means that everything to the right will be saved as URLs. In fact, because he already have values for URLs this will overwrite our previous values.
paste0(“http://www.transfermarkt.com”,URLs)
This will ‘paste’ together the string between the “” to each element within the list of URLs
Select our new line and press run and once the code as run, in the console type : print(URLs)
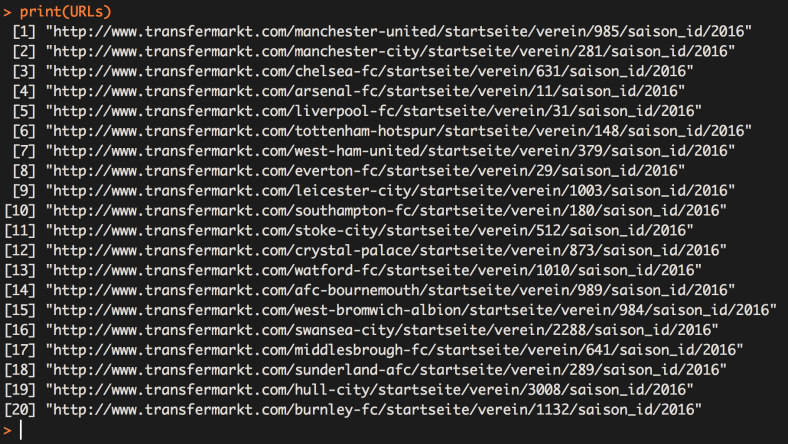
Great stuff, we have now successfully scraped the links to all club overview pages within the EPL and fixed them so they will actually work. There is lots of information on the club overview pages that we can scrape, however we are creating a list of the pages so we can get R to loop through the whole league once we decide on which data we want to scrape.
In Part 2 we will once again be scraping web links but via a loop. Loops are our friends. They allow us to process a lot of pages at once and automate the collection of a large amount of data once we set them up right.
Please leave comments or questions below.

Hey, I have got “.hide-for-pad .tooltipstered” using the SelectorGadget tool. I have verified and I only have 20 items selected but when I run the code in R, I’m getting a empty character list.
z1 % html_nodes(“.hide-for-pad .tooltipstered”) %>% html_attr(“href”) %>% as.character()
LikeLike