This mini-tutorial series aims to give the total beginner a few pointers in the direction of scrapping football data from the web.
Part 1 : Introduction & Scrapping a List of Web Links of Clubs
Part 2 : Loop Through the Web Links and Scrape a List of Web Links of Players
Part 3 : Loop Through the Player Links and Collect the Name and TM Value of the Players
Part 4 : Using ggplot2 to Create a Density Graph of Players Values within the EPL [up soon]
DISCLAIMER: The data we collect from transfermarkt.com should only be used for private use
At the end of Part 2 we finished with a list of URLs of each Player’s Overview Pages in squads for the EPL 2016/17 Season.
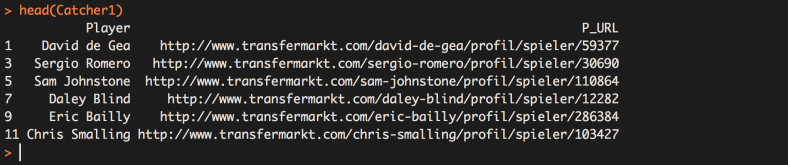
In Part 3 we are going to create a ‘loop’ which will go through each of our Player URLs and extract information from each of them. The information we will be extracting is the player’s ‘Market Value’, however we could grab pretty much any info from the player page. To keep things simple and to illustrate the process I have chosen to just concentrate on scraping the market value, thus leaving us with a list of 516 EPL players and their market value.
To achieve our goal we will once again use a ‘for’ loop in very much the same way as we did in part 2.
Step 1 : Setup the Empty Data Frame to Store Data
As we loop through the player webpages in our list we want to store the information in a safe place. Within R, data can be stored in data frames. To catch our data that is generated by our loop we will once again create an empty data frame that we fill up as we run the loop of code.
library(rvest)
URL <- "http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1"
WS <- read_html(URL)
URLs <- WS %>% html_nodes(".hide-for-pad .vereinprofil_tooltip") %>% html_attr("href") %>% as.character()
URLs <- paste0("http://www.transfermarkt.com",URLs)
Catcher1 <- data.frame(Player=character(),P_URL=character())
for (i in URLs) {
WS1 <- read_html(i)
Player <- WS1 %>% html_nodes("#yw1 .spielprofil_tooltip") %>% html_text() %>% as.character()
P_URL <- WS1 %>% html_nodes("#yw1 .spielprofil_tooltip") %>% html_attr("href") %>% as.character()
temp <- data.frame(Player,P_URL)
Catcher1 <- rbind(Catcher1,temp)
cat("*")
}
no.of.rows <- nrow(Catcher1)
odd_indexes<-seq(1,no.of.rows,2)
Catcher1 <- data.frame(Catcher1[odd_indexes,])
Catcher1$P_URL <- paste0("http://www.transfermarkt.com",Catcher1$P_URL)
Catcher2 <- data.frame(Player=character(),MarketValue=character())
Let me break down the new line:
Catcher2 <-
This segment means that everything to the right will be saved as Catcher2
data.frame()
This fucntion creates a data frame
Player=Character()
We create a string variable within our data frame called Player. This can be named anything but Player names sense in this occasion.
MarketValue=Character()
We create a string variable within our data frame called MarketValue which will eventually contain all market value information.
Select the new line of code. Run it. We have now created our data.frame to store the information.
Step 2 : Create the Overall Structure of the ‘For’ Loop
There are different types of loops but we are going to once again use a ‘for’ loop. Simply … ‘For’ each item in this list do this _____.
library(rvest)
URL <- "http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1"
WS <- read_html(URL)
URLs <- WS %>% html_nodes(".hide-for-pad .vereinprofil_tooltip") %>% html_attr("href") %>% as.character()
URLs <- paste0("http://www.transfermarkt.com",URLs)
Catcher1 <- data.frame(Player=character(),P_URL=character())
for (i in URLs) {
WS1 <- read_html(i)
Player <- WS1 %>% html_nodes("#yw1 .spielprofil_tooltip") %>% html_text() %>% as.character()
P_URL <- WS1 %>% html_nodes("#yw1 .spielprofil_tooltip") %>% html_attr("href") %>% as.character()
temp <- data.frame(Player,P_URL)
Catcher1 <- rbind(Catcher1,temp)
cat("*")
}
no.of.rows <- nrow(Catcher1)
odd_indexes<-seq(1,no.of.rows,2)
Catcher1 <- data.frame(Catcher1[odd_indexes,])
Catcher1$P_URL <- paste0("http://www.transfermarkt.com",Catcher1$P_URL)
Catcher2 <- data.frame(Player=character(),MarketValue=character())
For Loop Code – Line 1
As previously we want to ‘read’ a webpage into R in order to access the elements we want to scrape.
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
}
WS2 <- read_html(i)
We therefore assign WS2 (web scrape 2, but can be named anything) with the information from each webpage. The URL changes each time R loops through the code as we allocate ‘i’ into the () of read_html.
Code Line 2
We want to scrape each player’s name from the players’s overview page. To do this, we first open up one of the club overview page – lets open up David De Gea‘s We need to follow the same process in Part 1 and Part 2 by using SelectorGadget to isolate the element we want to extract. In this case the Player’s market value. After selecting the element I want and then deselected unwanted elements I am left with just 1 item which has the unique CSS identifier of “.dataMarktwert a”. There are two places where the market value is displayed, we will take the big one (as below) as this is the one that each player’s page actaully has.
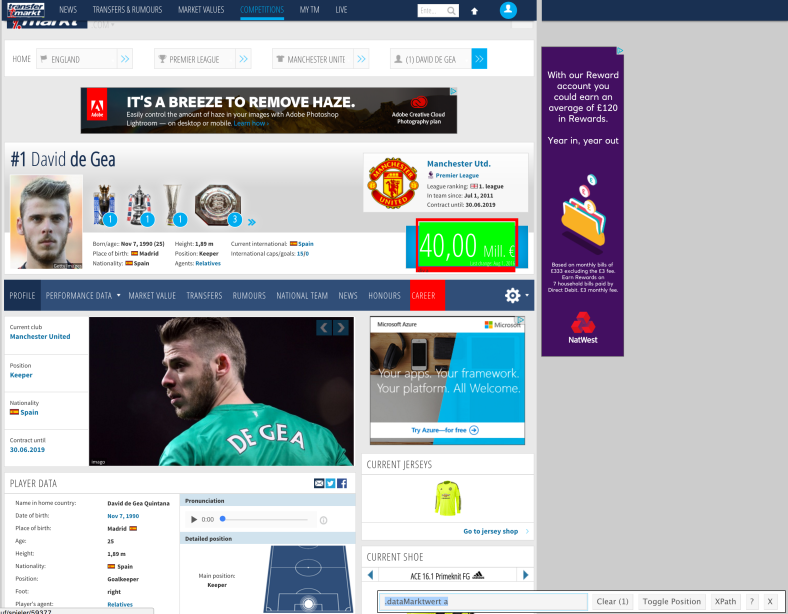
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
MarketValue <- WS2 %>% html_nodes(".dataMarktwert a") %>% html_text() %>% as.character()
}
MarketValue <-
This segment means that everything to the right will be saved as a variable called MarketValue
WS2
Is simply selecting our read webpage
html_nodes(“.dataMarktwert a”)
Selects all elements that match the unique CSS identifier that we ascertained from our work with SelectorGadget.
html_text()
We want to take the displayed text of the element.
as.character()
Saves the selected items as a string
%>%
As explained in Part1 This is called piping and is used to link bits of code together and pass information from one bit of code to the next. It makes coding is R much quicker and more logical.
Code Line 3
We also want to store the players name which we will rescrape (there are much better ways of doing this but I want to keep things specific to the scrapping process.
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
MarketValue <- WS2 %>% html_nodes(".dataMarktwert a") %>% html_text() %>% as.character()
Player <- WS2 %>% html_nodes("h1") %>% html_text() %>% as.character()
}
Player <-
This segment means that everything to the right will be saved as the variable Player
WS2
Is simply selecting our read webpage
html_nodes(“h1”)
Selects all elements that match the unique CSS identifier that we ascertained from our work with SelectorGadget.
html_text()
We want to take the displayed text of the element.
as.character()
Saves the selected items as a string
%>%
This is called piping and is used to link bits of code together and pass information from one bit of code to the next. It makes coding is R much quicker and more logical.
Code Line 4
Once the code collects all data we want to store this within the empty dataframe we created called Catcher2. The first step of doing this is by creating a simply temporary dataframe which we will use to quickly store the data for the team we scrapped. We call it ‘temp2’. It will consist of the ‘Player’ variable and the ‘MarketValue’ variable.
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
MarketValue <- WS2 %>% html_nodes(".dataMarktwert a") %>% html_text() %>% as.character()
Player <- WS2 %>% html_nodes("h1") %>% html_text() %>% as.character()
temp2 <- data.frame(Player,MarketValue)
}
temp2 <-
This segment means that everything to the right will be saved as temp
data.frame(Player,MarketValue)
This creates a data frame with the columns Player, and MarketValue
Code Line 5
Now we are in a great position of having the data from the club’s page in a dataframe but unless we save that data to our Catcher1 dataframe as the code loops through the next club it will simply overwrite the ‘temp’ dataframe and we will be only left with the data from the last club in the loop. We are going to use the ‘rbind’ function which sticks the rows of dataframes together with ease (as long as the columns are the same in name and number).
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
MarketValue <- WS2 %>% html_nodes(".dataMarktwert a") %>% html_text() %>% as.character()
Player <- WS2 %>% html_nodes("h1") %>% html_text() %>% as.character()
temp2 <- data.frame(Player,MarketValue)
Catcher2 <- rbind(Catcher2,temp2)
}
Catcher2 <-
This segment means that everything to the right will be saved as Catcher2, but because we already have a dataframe called Catcher2 it will simply overwrite it with the new code.
rbind(Catcher1,temp)
This takes both dataframes we want to paste together and joins them effortlessly. This has essentially filled up Catcher2 with the information from the scrape and stored it safely outside of the loop. Fantastic progress!
Code Line 5
When we run web scrapping code it sometimes takes a long time to complete the process and return the results, as you wait you have no idea if the code is running properly or not. If would therefore be useful if we added some sort of indication of progress, we do this with the cat() function.
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
MarketValue <- WS2 %>% html_nodes(".dataMarktwert a") %>% html_text() %>% as.character()
Player <- WS2 %>% html_nodes("h1") %>% html_text() %>% as.character()
temp2 <- data.frame(Player,MarketValue)
Catcher2 <- rbind(Catcher2,temp2)
cat("*")
}
cat(“*”)
When the looping code reaches this line it will print * to the console, this will give us an extremely basic indication in the code is running well and pages are being scraped. You can replace the * with anything that you want to be printed to the console “Processed”, “Grabbed”, “Get in!”. Try an alternative.
Step 3 : Run the Code and Hit a Wall
Select all of the new code we wrote today and press run… This is going to be great, effortless grabbing of data… I feel so pleased with my self! But…. we run into a problem!
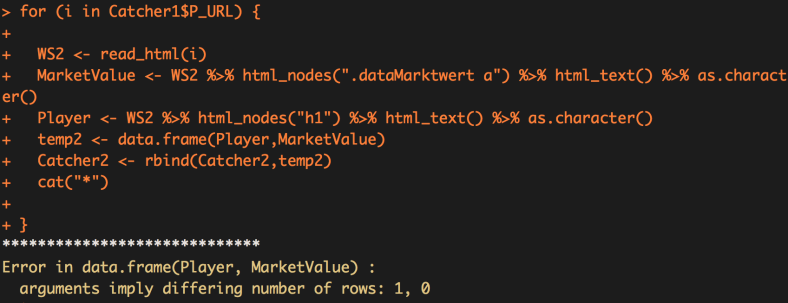
We get the error message: “Error in data.frame(Player, MarketValue) : arguments imply differing number of rows: 1, 0”. When I first encountered this I didn’t know what the hell it meant and naturally I went straight to StackOverview to find an answer.
It turns out that one of the pages doesn’t have some of the information we want to scrape, so when I try and create the temp2 dataframe it doesn’t have all the information needed so stops the process with an error.
To understand why I need to know which webpage caused the error. In the console, type ‘i’ and press enter.

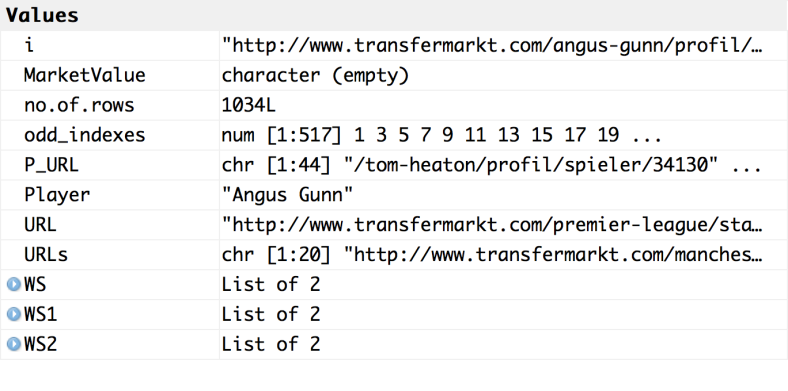
Who would have thought it, its that 196cm tall spanner in the works.. Angus Gunn! Let’s go to his URL to find out what might be happening. Ah… there is no MarketValue box as he currently has not been assigned a Market Value by TransferMarkt.
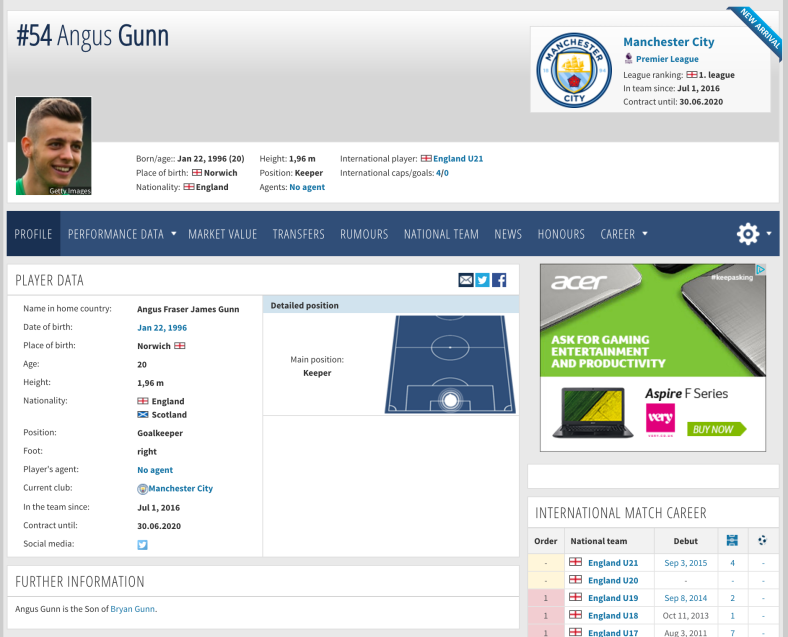
We could also ascertain what was missing by looking in the ‘Environment’ tab and we would quickly notice that the MarketValue value shows “character (empty)”.
 The Fix
The Fix
Before we think about the code to use, lets reflect on what our solution could be in plain English:
“If a player doesn’t have a MarketValue we want to skip the rest of the process, else we continue as planned”
Eurkea… we need to utilise an “IF” statement within our loop code to solve the problem. The final code will be like this:
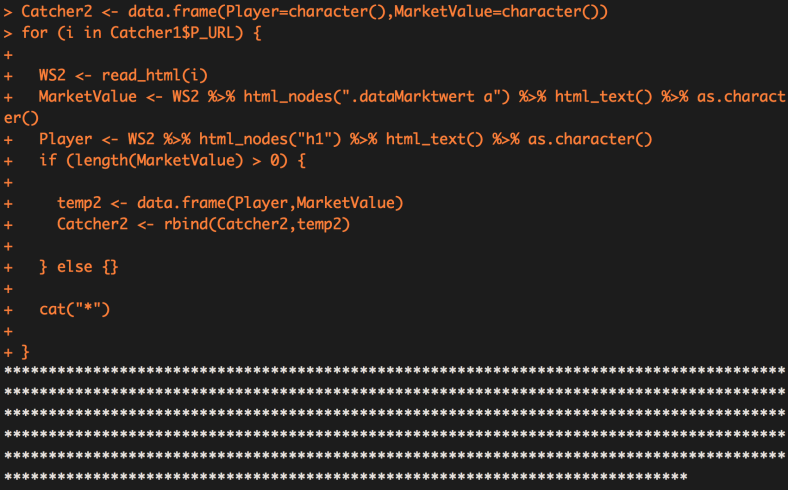
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
MarketValue <- WS2 %>% html_nodes(".dataMarktwert a") %>% html_text() %>% as.character()
Player <- WS2 %>% html_nodes("h1") %>% html_text() %>% as.character()
if (length(MarketValue) > 0) {
temp2 <- data.frame(Player,MarketValue)
Catcher2 <- rbind(Catcher2,temp2)} else {}
cat("*")
}
Explaining the IF Statement
An if statement in R can be explained in plain English as :
if (*this is true*) {*do this*} else {*do this*}
And in our situation:
if (MarketValue is empty) {Fill temp2 and bind with Catcher2} else {skip}
To find out if MarketValue is empty we use:
length(MarktValue) > 0
If a string variable is empty then it doesn’t have length, so if a string variable is not empty then it has to have a length of greater (>) than zero.
The rest of the final IF statement should be simple to understand, including the fact I have put nothing in the else{}. This is intentional, as I want nothing to happen if MarketValue is missing so the loop just moves onto the next one.
Now when we run today’s adjusted code it loops through all of the players and collects the MarketValue data. This will take a bit of time to complete but because we used cat(“*”) we will be able to tell if the process is running smoothly.
Now lets check out results by entering head(Catcher2) to the console, the head() function prints just the top 6 rows of our dataframe for us to look at without having to print all 514 rows! Which leaves us with this:
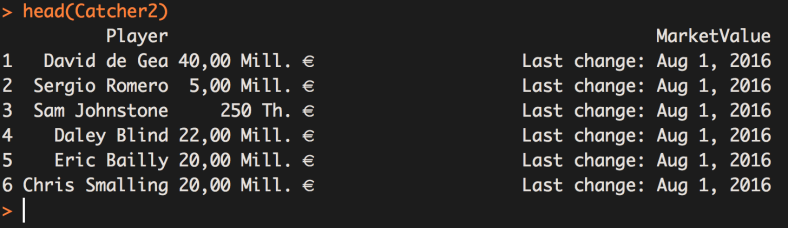
Bingo!! We have collected all of the Market Value figures for every player (-3 who haven’t been assigned a value yet) in the EPL for the 2016.17 season. We have also grabbed some info on when the value lasted changed. In Part4 we will learn how to trim away the information we don’t need from the MarketValue string and convert it to a number so we can use it in a number of different ways. Including creating a density plot of Market Values of the EPL.
Final Code for Part 3
library(rvest)
URL <- "http://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1"
WS <- read_html(URL)
URLs <- WS %>% html_nodes(".hide-for-pad .vereinprofil_tooltip") %>% html_attr("href") %>% as.character()
URLs <- paste0("http://www.transfermarkt.com",URLs)
Catcher1 <- data.frame(Player=character(),P_URL=character())
for (i in URLs) {
WS1 <- read_html(i)
Player <- WS1 %>% html_nodes("#yw1 .spielprofil_tooltip") %>% html_text() %>% as.character()
P_URL <- WS1 %>% html_nodes("#yw1 .spielprofil_tooltip") %>% html_attr("href") %>% as.character()
temp <- data.frame(Player,P_URL)
Catcher1 <- rbind(Catcher1,temp)
cat("*")
}
no.of.rows <- nrow(Catcher1)
odd_indexes<-seq(1,no.of.rows,2)
Catcher1 <- data.frame(Catcher1[odd_indexes,])
Catcher1$P_URL <- paste0("http://www.transfermarkt.com",Catcher1$P_URL)
Catcher2 <- data.frame(Player=character(),MarketValue=character())
for (i in Catcher1$P_URL) {
WS2 <- read_html(i)
MarketValue <- WS2 %>% html_nodes(".dataMarktwert a") %>% html_text() %>% as.character()
Player <- WS2 %>% html_nodes("h1") %>% html_text() %>% as.character()
if (length(MarketValue) > 0) {
temp2 <- data.frame(Player,MarketValue)
Catcher2 <- rbind(Catcher2,temp2)
} else {}
cat("*")
}

when will you publish the last part?
LikeLike
Over the next few days, hope you are finding it useful
LikeLike
yes. it helps me a lot. it’s the first time i’m web scraping with R!
Can you recommend any other articles where you can’t use the Selector Gadget, because the data isn’t visible on the website. Where the things you’re looking for are just on the site when you press Ctrl+U in Chrome? you know what i mean?
LikeLike
Thanks for doing this, it has been really, really helpful! Looking forward to the final part.
LikeLike
Thanks Nath, I am very late on part 4 and aim to complete it asap!
LikeLike
Thanks a lot. When will part 4 be available ?
LikeLike